I'm probably wrong, but...
Selecting random MongoDB objects, optimised with Redis
Redis is a great tool, it powers some of the largest websites in the world. MongoDB too, is likewise very popular and useful.
I maintain fnbr.co, a Fortnite cosmetics directory. It has a very popular feature: the randomiser. Here people can choose a random outfit from all available items. Up until recently, this used to send queries to Mongo which worked ok, but I wanted to improve the performance both on the backend and latency to the end user.
The old method
Fortunately, Mongo has a built-in way to fetch a random 'sample' of documents - you can read more about it here.
This approach is useful because it allows you to use Mongo's powerful query language and exclude certain documents or match certain criteria.
This is the query that used to be ran for each request to /api/random?type=outfit:
db.getCollection('Items').aggregate([{ '$match' : {type: 'outfit'} }, { '$sample': { size: 1 } }])
I briefly mentioned a benefit above: we can exclude certain documents, for example the last result the client got - guaranteeing it won't come up in this request.
However, a big drawback is that it executes directly on the Mongo server and isn't scalable. As I mentioned in earlier posts, the site has replicas around the world.
At the time of writing we have Amsterdam, Sydney, Miami and San Francisco along with the main cluster in New York. The replica servers do not have access to Mongo, but do have a read-only slave of the Redis instance, meaning anything cached in New York is immediately available locally.
So ideally, I wanted to make use of these replica servers for performance reasons (distribute the load more evenly across the fleet) and reduce latency for the end user (a user in Europe, doesn't have to send a request to the New York servers, instead it goes to an Amsterdam one)
A better solution
With this in mind, I found the srandmember command within Redis' documentation. This will grab N random elements from a set.
Next I had to create a set for each item type where each set member was the ObjectId of an item. Which would then be matched up to the key fnbr_items:object-id-here in Redis.
As previously these didn't exist I created a cron task to populate it every 20 minutes from Mongo, very basic item info is stored in each item key (name, type, price, image links) as it is only needed for the randomiser.
However, people can also view individual item pages in the URL format /type/slug (for example /pickaxe/reaper) which caches all the information we have about an item including its shop occurrence history in the key fnbr_items:object-id-here for a short period for future visits.
When an item is requested here it checks if the item has the revalidate property set to true, meaning only basic information is available and the cache needs to be refilled from Mongo data.
This isn't an issue for the randomiser, but gives you a bit of context as to how the cache works and is populated.
So the new method is like this:
// Get a random item id of this type
Redis.use().srandmember('fnbr_types:' + type).then((key) => {
if(key) { // Key was found
// Lookup the item by id
Redis.use().get('fnbr_items:' + key).then((item) => {
if(item) {
// Parse it and respond
// ...
} else if(config.replica) { // Item not cached, this server cannot continue
return reject({status: 503, error: 'Service unavailable', errorMessage: 'Cache incomplete, please retry request on main cluster'});
} else { // Item not cached, lookup in mongo
return lookup(key).then(resolve);
}
});
} else if(config.replica) { // No keys available, cache might need rebuilding
return reject({status: 503, error: 'Service unavailable', errorMessage: 'Cache unavailable, please retry request on main cluster'});
} else { // No key was found, find one in mongo the old way
return lookup().then(resolve);
}
});
Note: We do lose the ability to exclude certain elements from the possible results, however this isn't a big issue because the chance of collision is so low and it is very easy to fetch another.
And the performance speaks for itself, according to NewRelic the requests were being answered on average in under 7 milliseconds.
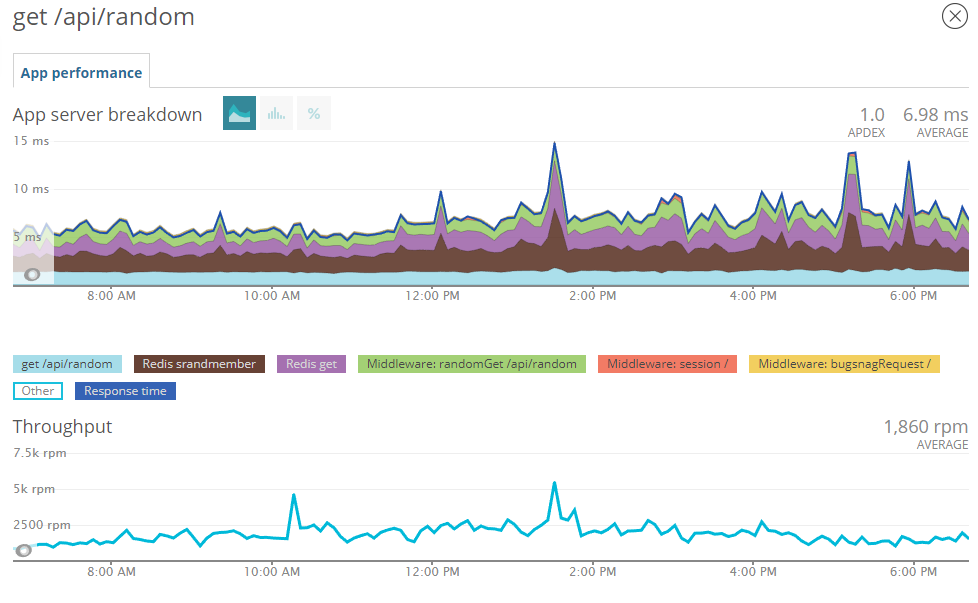
This didn't seem to increase, regardless of the load, the average load is about 2,000 requests per minute but at peak time we can get anything as high as 10,000 per minute.
Reducing latency
Now that I had a viable method to find random items for each item type, I needed to deploy it. One of things I didn't like about the old system was that it was only usable on the New York cluster of servers which had two main downsides (increased server load there and high latency for end users not in North-East America) as well as being a single point of failure.
As I mentioned before, we currently have servers in 4 other cities and now that the data was available in Redis the replica servers can of course access it.
Initially, I decided to make the client send a request to /api/ping which simply returns the Cloudflare PoP the request went through and the load balancer that should be used for future requests, usually the geographically closest.
Although I recently changed it to decide the load balancer before the page loads by appending some JSON to the page HTML sent by a Cloudflare worker, removing an additional HTTP request.
After the client knows which server to use, it sends all api requests to it, if one fails (very rare) it automatically retries on the main cluster of servers in New York which can access the database if necessary.
The result of this is that instead of requests taking over a second (especially from Australia/NZ and Asia) to complete in some cases, most requests now complete in under 100ms.
As a large percentage of our traffic is from mobile users, the latency impact is even more prominent where even a small decrease is really helpful.
Not perfect for everyone
This setup works great for us, but isn't ideal for everyone. Not everyone is able to cache their entire dataset in Redis.
In case the cache fails or is missing an item I do have a fallback to the old method of using the Mongo $sample operator. This could be used to gradually fill the cache for datasets which aren't as concise as ours.
Unfortunately, we don't have any servers in South America which is a popular region for the site. This is just because of the high cost of South American servers and bandwidth, along with the lack of choice of cloud providers.
Thank you for taking the time to read this post, I hope you found it interesting and will give the randomiser a try here!
I will be writing another post shortly about the search function added to the website recently, which uses a similar Redis based system to cache and access the data fast.